


統計解析は確率ですから、当然確率論で判断することのリスクも当然あります。
間違って判断してしまうケースによりαエラー、βエラーと呼びます。
また、論文を読んでいるとαエラーと検出力(power)という言葉を目にすると思います。
それぞれどういうことを表しているのかαエラー、βエラー、検出力について簡単に説明したいと思います。
Contents
αエラー
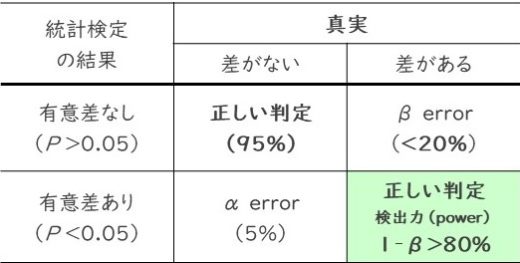
αエラー(第1種の過誤)とは『本当は差がないのに、差があるという間違い』のことです。
αエラーを起こす可能性が5%だとすると「100回に5回は本当は差がないのに有意差ありとなる可能性がある」ということを意味します。
つまり偽陽性です。
覚え方ですが、本当は差がないのに慌てて差があると判断してしまった、“あわてんぼうのαさん”と覚えると良いと思います。
βエラー
βエラー(第2種の過誤)とは『本当は差があるのに、差がないという間違い』のことです。
βエラーを起こす可能性が20%の場合は「100回に20回は本当は差があるのに、有意差なしとなる可能性がある」ということを意味します。
つまり偽陰性です。
覚え方ですが、本当は差があるのにぼーっとしていて見逃してしまった、“ぼんやりもののβさん”と覚えると良いと思います。
この危険性は、本当は差があったのに感度が下がっていたために起きているので、症例数を増やすことでいくらか解消します。
検出力(power)
検出力(power)は『本当に差があるときに差があるという確率』のことです。
検出力=1-βで表されます。
例えばβエラーを起こす可能性が20%の時は「100%-20%=80%」ですので、検出力は80%ということになります。(一般的には検出力80%以上で設定されます。)
『本当に差があるときに差があるという確率』のことですから、検出力の大きいものほど厳しい検定であるということになります。
まとめ
- αエラー(第1種の過誤):あわてんぼうのα
・『本当は差がないのに、差があるという間違い』(偽陽性)
・一般的にはαは5%(未満)で設定される - βエラー(第2種の過誤):ぼんやりもののβ
・『本当は差があるのに、差がないという間違い』(偽陰性)
・一般的にはβは20%未満で設定される - 検出力(power)
・検出力=1-βerror
・『本当に差があるときに差があるという確率』
・検出力の大きいものほど厳しい検定
αで表される有意水準とは『設定した仮説が本当は差がないのに誤って「差がある」としてしまう確率』のことですから、P値はαエラーの発生率という捉え方もできますね。
有意水準とP値について詳細はコチラの記事をご覧ください。

さて、少し話は変わりますがαエラー、βエラー、検出力はサンプルサイズを計算する際に使用されます。
サンプルサイズとは各群どれだけの人数を調べるかということです。
自分でサンプルサイズを計算するわけではないので、詳しく理解する必要はないのかもしれませんが、αエラー、βエラー、検出力はよく出てくる言葉になるかと思いますので知っていて損はありません。
論文の批判的吟味ではαエラーと検出力(=1-βエラー)について記載されていると、適当に何人くらい集めましたではなく、しっかり統計的にサンプルサイズを計算しているということが客観的に確認できるということが大事です。
そのため、論文の批判的吟味では最低限αは5%未満か検出力は80%以上ということが記載されていることを確認できれば良いと思っています。(記載されていない論文も多いと思いますが…)
最後に少し逸れましたが、この記事でαエラー、βエラー、検出力について言葉の意味やなんとなくのイメージが掴むことができれば良いと思います。
皆様の応援が励みになります。
1日1回、クリック(↓)をよろしくお願いします。
![]()












